Images
Images I love. A bit from everything. Warning: Can contain nudity, violence and other similar topics!
Ashes of Phoenix
The best game I have ever played. A passion-project that deserves everyones attention.

About me
Just a small page containing things about me. I add some info from time to time. Don't expect a diary or something along those lines!

Cats! They will blow your mind.
Look at this cute cat! Isn't it cute? No? What monster are you then? Yes? Goooood!

Oh yeah, forgot to tell you. I am a snake, but see for yourself.
Snakes are no animals to be afraid of! Really! If you are afraid of snakes than you will be afraid of me... So please. Don't be afraid of snakes!

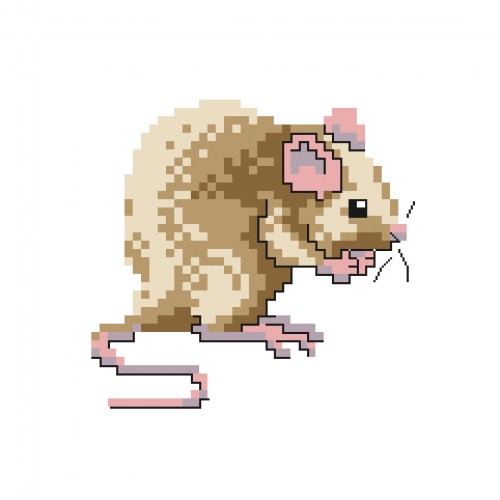
And lastly, this one. A rat.
Rats are cute, and to top that! They are intelligent. That's right! Intelligent! I had a rat as a pet! But sadly, they do not live long lifes... 3 years is a good average.